I spent today building out offline mapping support for the maps feature in the Pedometer++ v5 update. If you are an astute reader of this diary you’ll recognize that sounds an awful lot like a new feature…and only last week I put up a sign in my office that prominently forbade any new features.
Well…let me explain.

I was startled awake this morning at 5am, apparently my brain had a rogue background thread running this whole time trying to work out how I could efficiently support offline maps and especially how I’d then share the downloaded tiles to the Watch.
Well, when I woke up I had a clear idea about how to efficiently solve this problem and how to determine which tiles to download. Moments of clarity and inspiration like this are very rare, so I promptly ignored the sign on my monitor and got to work.
Determining the Tileset
The first problem I had was working out which mapping tiles I should download for a given route. A route is a collection of ordered GPS coordinates. Then for the map itself I’m creating a map from a collection of individual tiles, each which corresponded to a particular span of the earth. Specifically I’m using a “Slippy”/XYZ map setup (well explained here).
Now I could just find the GPS coordinates at the corners of my route (min/max Latitude & Longitude), and then download all the tiles inside that rectangle. But this approach would require a download of way more tiles than the user actually would need to complete their walk. Imagine the “worst-case” scenario where they walked in a perfect diagonal from south-east to north-west. The rectangle of that route would have many tiles literal miles away from them, which aren’t relevant.
Tiles also cost me money. So while it is also just slower for the user to spend time on tiles they’ll never see, it also would be expensive to take this “naïve”.
So instead I need to find a way to determine which tiles in the grid they actually would intersect with. This is the part that had stumped me for a while. It sounded a lot like I’d need some kind of deep GIS algorithm or spatial reasoning to accomplish this. The insight which awoke me this morning was that instead this is actually extremely similar to the computer graphics problem of line drawing.
If you want to draw a line on a pixel screen you can’t actually just “draw the line”, you have to instead determine which of the screen’s pixels would closest match the desired, pure line, and illuminate those. In practice, on modern devices, this often involves much more sophisticated anti-aliasing algorithms and optimizations but a basic line drawing algorithm would solve my problem perfectly.
What I can do is find the integer tile-index (X & Y) for each endpoint of the path segments and then “draw a line” between them to find which subsequent indices would be traversed to travel between them. I ended up using the Bresenham variant of this because it was supposed to be the very efficient. Though any basic variant would have worked.
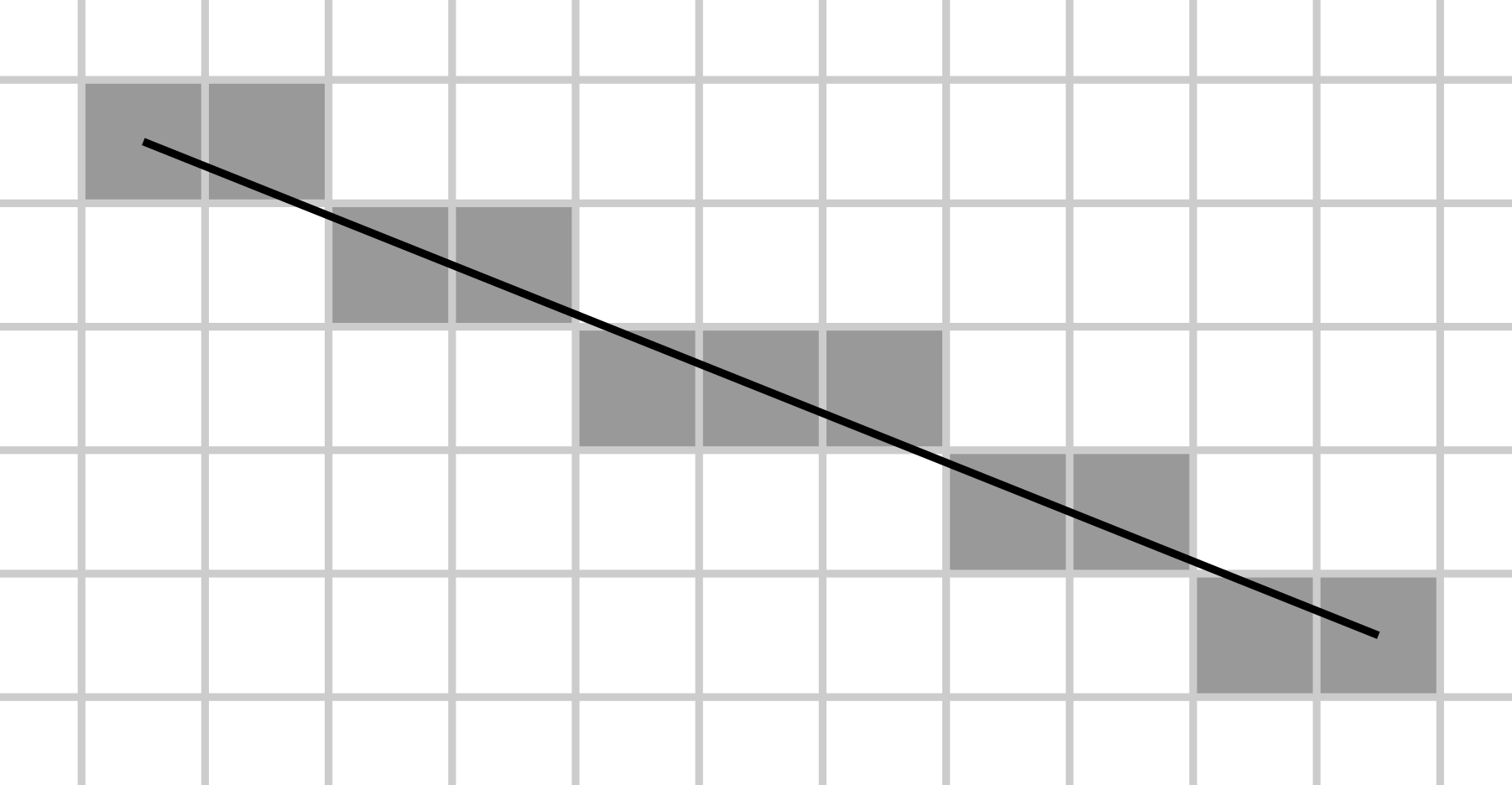
This ‘sparse’ path is too severe in practice for showing on a map because I won’t be displaying only the actual path tiles, but also the surrounding tiles on the map. So for each of the resulting tiles I also add each of its adjacent tiles (8 in total). I do this using Set to efficiently ensure that I don’t have any duplicate tiles in the collection.
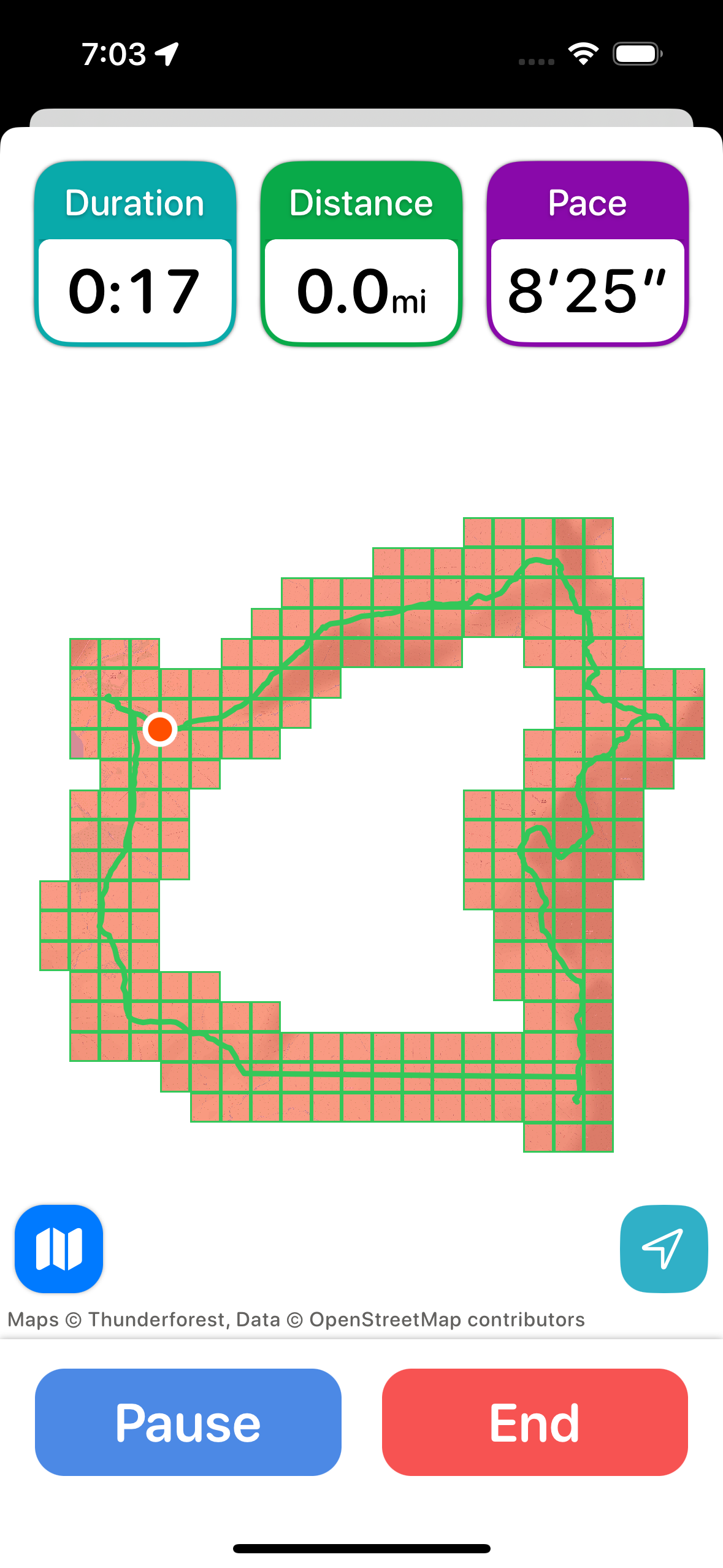
I repeat this for each required zoom level and boom…I have the tiles required.

The examples seen above are abnormally zoomed up for testing purposes. Typically the UI will be centered on the path area and the red area fill the screen.
The result was better than I could have hoped for. It seems to perfectly capture the desired set of tiles I wanted and runs very quickly.
For a typical 7-8mi day trip hike this results in around 500 tiles being required for offline download. For my massive 26mi testing file it would require 1,300. For comparison the large data set would have required around 16,000 tiles with the rectangular solution.
These tilesets seems very reasonable to work with. The large one would take around a minute to download and the typical ones are more in the 20-30sec range.
Conclusions
This diary is quickly turning into Algorithm Corner, but hopefully it is still helpful.
Realtalk: I get super intimidated when talking about and looking at “fancy algorithms”. Many of them go over my head and I really struggle to understand them…and I have a degree in Computer Science! So what I instead do is just focus on trying to use the simplest forms of a method I can understand, and work from there.
I also will try to write down things on paper, which I find really helps me get a grasp on them.
This process also gets easier with time, so if you are still in the “wow this is hard” phase, don’t get discouraged. That is where we all start and it will improve with experience.
Also, remember that nothing is obvious until it is properly explained and understood.
Today’s diary entry was again way down in the weeds…so I have a little reward for those who got this far. Before I post the TestFlight link for this Pedometer++ update broadly, I’m going to post it here. If you are interested enough in this project to read all that, you deserve first dibs on trying it out.
I’ll be opening up the beta more generally later this week.